How I Taught My Issue Tracker to Dispatch Coding Agents
Last month I ran Claude Code on 12 GitHub Issues simultaneously. Three of them tried to modify the same file. Two got stuck in retry loops with no backoff. One silently burned through $40 in API tokens before I noticed it was hallucinating the same test fix over and over. By the time I untangled the mess, I had spent more time babysitting agents than I would have spent writing the code myself.
If you’ve tried running coding agents on real work, you’ve been here. The agent itself is capable. The problem is everything around it: workspace management, state tracking, failure recovery, and the constant vigilance required to keep things from going sideways.
The ad-hoc mess
Here’s what most teams do today. You write a bash script that clones a repo, checks out a branch, and launches claude with a prompt piped to stdin. Maybe you run it in a tmux session. Maybe you have a spreadsheet tracking which tickets are assigned to which agent. You are, in effect, building half an orchestrator every time, and building it poorly.
I know because I did the same thing. The failure modes are predictable:
No workspace isolation. Two agents working on different issues clone into the same directory or push to the same branch. Merge conflicts pile up. Neither agent knows the other exists.
No stall detection. An agent hangs waiting for a response that will never come. You don’t find out until you check hours later, or until your API bill tells you.
No state persistence. Your machine reboots, or the script crashes. Which issues were in-flight? Which retries were pending? All gone. You start over, hoping you remember where things stood.
No tracker reconciliation. Someone moves a ticket to Done in Jira while the agent is still running. The agent finishes, pushes a branch, and now you have orphaned work and a confused issue history.
No cost controls. An agent enters a retry loop or starts rewriting the entire codebase. There is no budget cap, no turn limit, no circuit breaker. You pay for the tokens and clean up the mess.
Each of these failures is fixable in isolation. Fixing all of them, reliably, while keeping things generic enough to work with different agents and different trackers, is a real engineering problem. I decided to solve it once.
What I built
Sortie is an open-source orchestrator that watches your issue tracker and dispatches coding agents to work on tickets. You configure everything in a single file called WORKFLOW.md, and the orchestrator handles the rest.
Here’s what a minimal WORKFLOW.md looks like:
---
tracker:
kind: github
api_key: $SORTIE_GITHUB_TOKEN
project: acme-corp/platform
query_filter: "label:agent-ready"
active_states: [backlog, in-progress]
handoff_state: review
terminal_states: [done]
agent:
kind: claude-code
max_concurrent_agents: 4
---
You are a senior engineer.
## {{ .issue.identifier }}: {{ .issue.title }}
{{ .issue.description }}
The YAML front matter declares the tracker connection, agent configuration, and operational parameters. The Markdown body below the closing --- is a Go template that becomes the agent’s prompt, rendered per issue with the ticket’s identifier, title, and description injected automatically.
When you run sortie, here’s what happens:
- Sortie polls GitHub Issues for tickets matching
label:agent-readyin the configured active states. - For each eligible issue, it creates an isolated workspace directory, keyed by issue identifier. No two agents share a workspace.
- It launches Claude Code with the rendered prompt, inside that workspace.
- While the agent runs, Sortie watches for stalls. If the agent produces no output for a configurable duration (
stall_timeout_ms), it gets killed and rescheduled with exponential backoff. - When the agent finishes, Sortie transitions the issue to
reviewin GitHub. - Every poll cycle, reconciliation checks whether the tracker state still matches the orchestrator’s internal state. If someone moved a ticket to Done externally, the running agent gets cancelled and the workspace gets cleaned up.
The orchestrator persists all state to SQLite. Kill the process, reboot the machine, come back tomorrow. Every in-flight session, pending retry, and run history record is still there. Sortie picks up where it left off.
Single binary, zero dependencies. No Postgres, no Redis, no message queue. SQLite is embedded via a pure-Go driver (modernc.org/sqlite), so the binary has no CGo requirement. Install it, point it at a WORKFLOW.md, and start it. That is the entire deployment.
Agent-agnostic. Sortie ships with a Claude Code adapter today. The adapter interface is small: launch a process, stream events, handle exit codes. Swap agent.kind in your config, and the orchestrator works the same way with a different agent.
Tracker-agnostic. Jira and GitHub Issues ship today. The tracker adapter interface handles fetching candidates, reading issue state, and writing transitions. You can add a new tracker without touching orchestrator code.
Cost controls are built in. max_concurrent_agents caps parallelism. max_turns limits conversation turns per session. max_sessions limits how many times an agent can retry a single issue. For Claude Code specifically, max_budget_usd sets a per-session dollar budget. These aren’t afterthoughts pinned on with environment variables. They are first-class configuration because running agents without guardrails is how you get surprise invoices.
Workspace lifecycle hooks. after_create, before_run, after_run, and before_remove hooks let you plug in scripts at each stage: clone a repo, create a branch, format code, push changes. The hooks turn Sortie from a process launcher into a full automation pipeline.
Why not Symphony?
When OpenAI released Symphony, I read the spec carefully. It solves a similar problem: dispatching coding agents to tracked issues. But the trade-offs differ.
Symphony’s reference implementation is written in Elixir and labeled experimental. It targets Linear as its tracker and Codex as its agent. The spec marks tracker writes and pluggable adapters as TODO. There is no persistence layer, so state is lost on restart.
If you’re running Codex against Linear tickets, Symphony may work for you. If you need Jira or GitHub Issues, if you want retry logic that survives restarts, if you want to swap agents without rewriting your pipeline, it won’t.
These are young projects making different trade-offs. Sortie prioritizes production reliability: agent-agnostic adapters, tracker-agnostic adapters, SQLite persistence across restarts, and a Go single binary you can deploy anywhere.
Ad-hoc scripts remain the other common approach. They work for one-off runs but collapse under repetition. No persistence, no reconciliation, no retry logic with backoff. You trade engineering time for operational pain, repeatedly.
Getting started
Install the binary. On macOS or Linux, the install script detects your platform and puts sortie on your PATH:
curl -sSL https://get.sortie-ai.com/install.sh | sh
On macOS and Linux you can also use Homebrew: brew install sortie-ai/tap/sortie. If you have Go 1.26+, go install github.com/sortie-ai/sortie/cmd/sortie@latest works too. Prebuilt archives for all platforms (including Windows) are on the GitHub Releases page.
Create a WORKFLOW.md in your project directory with your tracker and agent configuration. The Quick Start guide walks through a complete example.
Run Sortie:
sortie --port 8080
Open localhost:8080 to see the built-in dashboard: running sessions, pending retries, run history, and current configuration.
Full documentation lives at docs.sortie-ai.com. The source is on GitHub, Apache licensed.
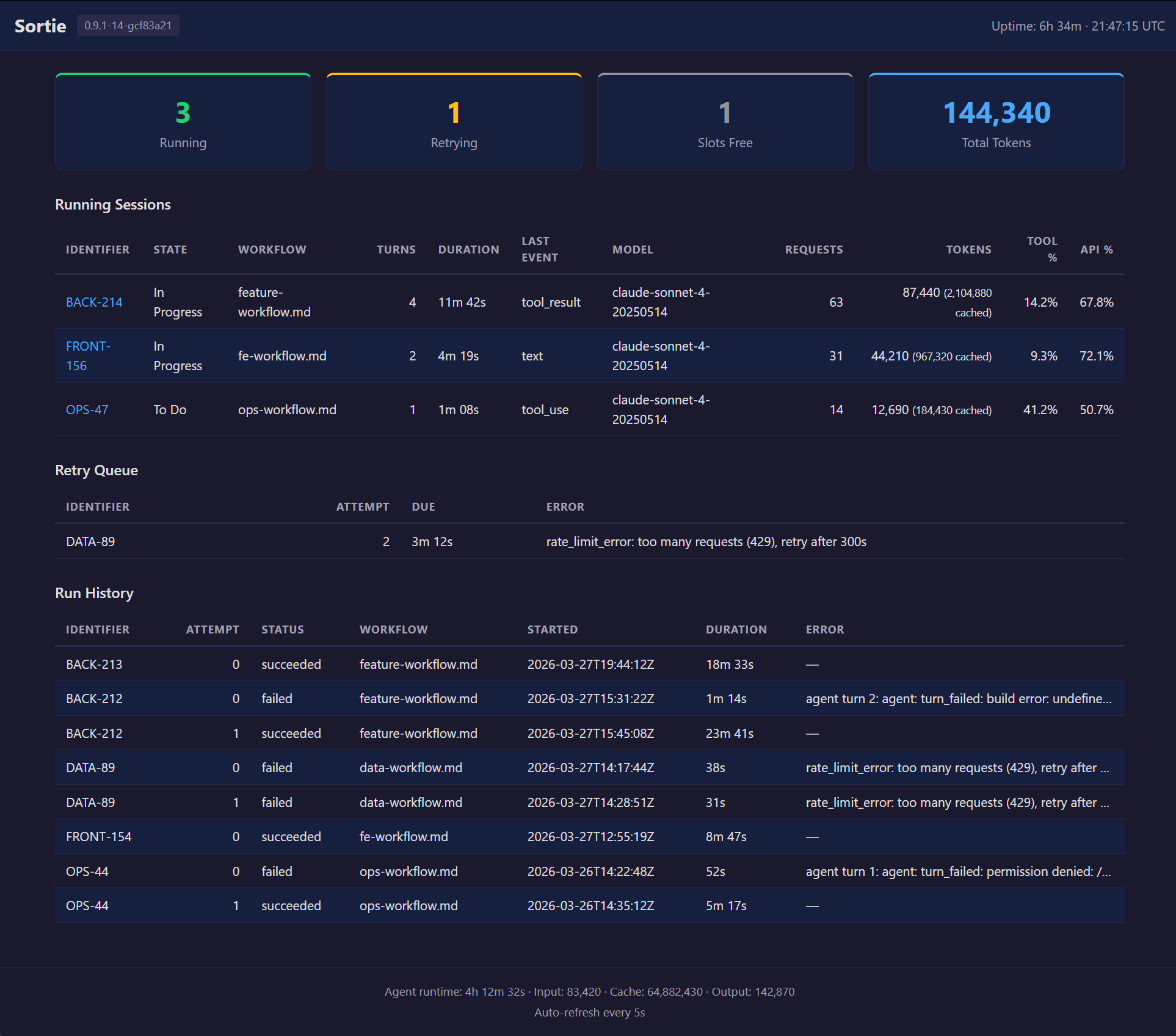
Figure 1: The Sortie web dashboard showing active agent sessions, pending retries, run history, and current configuration.
What’s next
A Copilot CLI adapter is in progress. Linear, GitLab, and Azure DevOps tracker adapters are on the roadmap. An agent tools API will let agents communicate structured data back to the orchestrator during a run.
If you’re automating coding agents and tired of reinventing the plumbing, give Sortie a try. Issues and pull requests are welcome.
